
How FraudGuard Runs on DigitalOcean
A candid production architecture tour of the compute, data, search, cache, deployment, and dedicated-environment systems behind FraudGuard.io.
Every application that touches the internet faces a constant stream of malicious traffic—bots, brute-force attempts, abuse from compromised IPs. Blocking those threats effectively requires deep, up-to-date intelligence about where they’re coming from and how they behave. But building that kind of visibility on your own means operating a global sensor network, correlating attack data over time, and maintaining the infrastructure to serve it all in real time.
That’s the problem I set out to solve by building FraudGuard.io. FraudGuard provides APIs for IP reputation and threat intelligence, powered by a long-running distributed honeypot network and an Attack Correlation Engine (ACE) that turns raw attack telemetry into actionable signals. The honeypot sensors run on dedicated infrastructure, but the resulting data still needs somewhere to land, get processed, and reach customers quickly. This post explains how the FraudGuard API runs on DigitalOcean in production: how we choose a datastore for each job, ship Laravel services on Droplets, use Spaces for uploads and offline database snapshots, and provision dedicated customer environments with Terraform.
What FraudGuard.io does
FraudGuard.io helps security and product teams make fast decisions about traffic: allow it, challenge it, or block it. Under the hood, our Attack Correlation Engine (ACE) correlates attacker signals across a global honeypot network, then turns that into simple outputs you can actually use: real-time IP lookups, bulk enrichment, advanced search, and offline database snapshots.
Why DigitalOcean
FraudGuard has customers with very different requirements. Some want a straightforward API. Others need dedicated resources for contractual requirements, isolation, load guarantees, or compliance reasons.
DigitalOcean makes that realistic for a small team because it’s a clean combination of:
- Strong primitives (networking, load balancers, regions)
- Managed data services we rely on heavily, especially DigitalOcean Managed Databases (MySQL, Valkey/Redis, MongoDB, OpenSearch)
- DigitalOcean Spaces for customer uploads and offline intelligence distribution
- A simple model that plays nicely with infrastructure-as-code, which makes non-production environments easy to spin up and tear down.
Areas I’d love to see DigitalOcean improve
We’ve been using DigitalOcean in some form since 2016, and it’s been a solid home for the parts of FraudGuard that run there. The points below aren’t deal-breakers, they’re just a few areas where a smoother workflow would make day-to-day operations even better.
- More ergonomic update APIs. For some resources, updates are full-object PUTs, which often means reading the current config, modifying a single field, and sending the whole object back to avoid unintentionally resetting attributes.
- Auto-scaling read capacity for Managed Databases. Standby/read-only nodes work well for scaling reads, and storage autoscaling is great; however having read nodes scale dynamically based on load would be a game changer.
What this looks like in production
I’m a big believer that architecture posts should show receipts. Here are two snapshots from the normal operation of our shared API cloud infrastructure. This shows what customers are actually using, and where attackers are showing up across the honeypot network.
API Usage
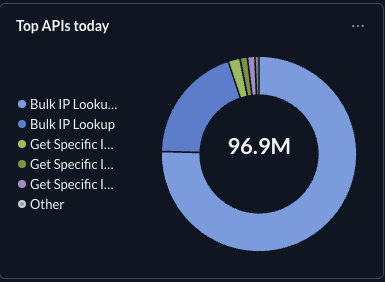
~96.9M API calls so far today, with Bulk IP Lookup driving the majority of volume.
Attackers by Country
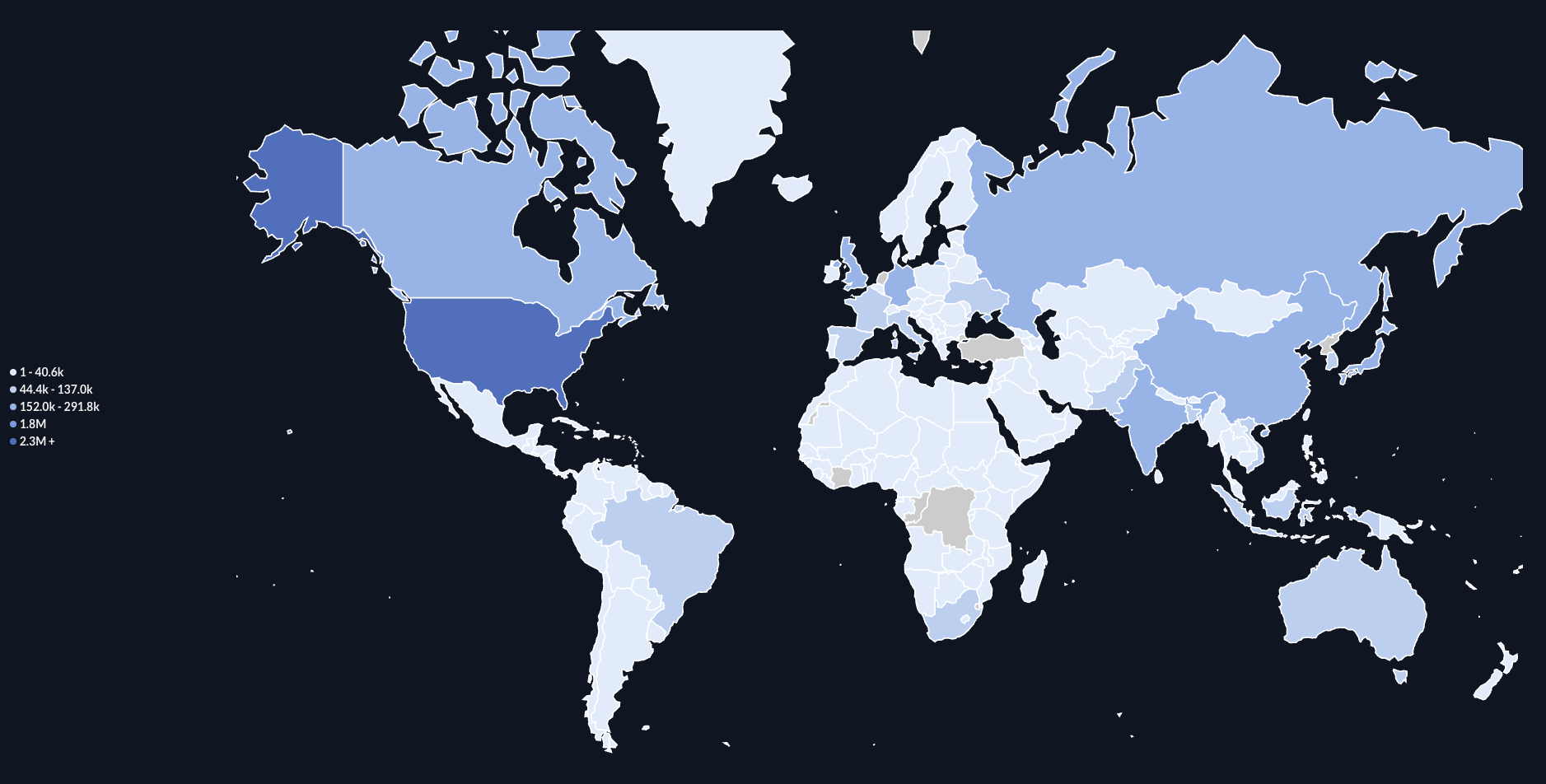
Attackers by country: a view of attacker activity detected across the honeypot network today.
Architecture at a glance
At a high level, FraudGuard looks like this:
-
Client traffic hits our edge and lands on a DigitalOcean Load Balancer.
Load balancer health checks are one of those unglamorous features that quietly make everything better. We rely on them for a “self-healing” effect at the edge: if an app server starts misbehaving (bad deploy, exhausted resources, wedged process), the load balancer will stop sending it traffic and keep requests flowing to healthy nodes.
In practice, this is critical for stateless API fleets:
- Fast failure isolation: unhealthy nodes get removed from rotation automatically.
- Safer scaling: newly bootstrapped Droplets only receive traffic once they pass health checks.
- Less pager noise: many transient issues self-resolve without manual intervention.
- Requests route to Laravel API servers running on DigitalOcean Droplets in autoscaling pools.
- The API layer fans out to the right datastore depending on the job.
-
DigitalOcean Spaces serves two major roles:
- Uploads every customer file upload lands in Spaces first. That gives us a durable landing zone for large artifacts and keeps our API/compute layer stateless.
- Offline intelligence distribution. We publish customer-ready snapshots of the ACE database to Spaces in CSV and SQLite formats so teams can use FraudGuard data offline or inside restricted environments without calling the API on every request.
On top of that:
- We run Metabase on DigitalOcean for dashboards and general analytics.
- We run a sizeable Jenkins cluster on DigitalOcean for batch workflows.
- We use DigitalOcean monitoring/alerts to stay ahead of capacity issues.
Dedicated customer environments
Apparently “we run in the cloud” isn’t enough anymore-now some customers want us to run in their cloud.
We have customers who require:
- Isolation from other tenants
- Dedicated compute/data for load reasons
- Region-specific deployment for policy, data residency, or latency reasons
With Terraform, we can stamp out a full environment: networking, compute, managed databases, object storage, and monitoring.
“DigitalOcean lets me spin up a dedicated, isolated FraudGuard.io environment for a customer with a single Terraform apply — in whatever region/account they need.”
Data layer deep dive
MySQL: durable truth + ACE derivations
MySQL is where the “durable truth” lives for FraudGuard — and where a lot of ACE’s derived intelligence is computed via stored procedures. It’s the database we trust for the stuff that has to be correct.
To be honest, this is also where things can get a little spicy. We’ve accumulated 10+ years of honeypot attack data in MySQL. You don’t just wake up one day with a “small, tidy database.” The way we keep it sane is by trying to be intentional about what belongs in MySQL and what doesn’t.
OpenSearch: fast investigative search
When customers need fast, flexible threat investigation—fast filtering, searching, investigative queries, and high-cardinality lookups across large datasets—we push those into OpenSearch.
We use it heavily for APIs like advanced threat lookup where query shape changes often and users expect fast, flexible filtering.
MongoDB: evolving event-shaped data
MongoDB is for data that naturally wants to be JSON documents: evolving schemas, structured event records, and “we want to add fields over time without turning every change into a migration.”
Redis: more than cache
We use DigitalOcean Managed Valkey/Redis as a core platform component-caching is only the beginning.
Redis is where we keep:
- TTL-governed volatile state
- Request-time counters and telemetry
- Rate limiting enforcement
- Time-window analytics
- Real-time “renderable” datasets
Compute + deployments
Our API servers are PHP (Laravel), running on DigitalOcean Droplets in autoscaling pools. We keep the compute layer intentionally simple:
- Standard Ubuntu LTS image
- Predictable dependencies
- Scale out, don’t handcraft
Every app is stored in GitHub, and deployments run through Laravel Forge. Forge is the control plane that keeps deployments consistent across environments and server fleets. It supports push-to-deploy workflows from Git and makes it straightforward to keep releases clean and repeatable.
New Droplets join the fleet via a startup/init script that wires them into the deployment workflow, so adding capacity doesn’t mean adding operational chaos.
“We treat Droplets like disposable compute — scale out and replace freely”
What we don’t do
This is where the boring reliability comes from.
- We don’t rely on Droplet snapshots/backups for recovery. Droplet config is IaC.
- We don’t write permanent keys to Redis. Every key we set in Redis has an explicit TTL. If it can’t expire cleanly, it doesn’t belong in Redis.
- We don’t force full-text search into SQL. That’s what OpenSearch is for.
- We don’t keep raw uploads forever. Spaces is treated as file staging; processing happens in our own proprietary model; then data is trashed.
Ready to try FraudGuard.io?
If you’re building anything that touches a critical application component, you’re already dealing with bots, agentic AI, automation frameworks, abusive traffic, and suspicious infrastructure.
FraudGuard.io gives you practical threat intelligence you can actually plug into systems:
- Real-time IP reputation lookups (single and bulk)
- Advanced investigative search when you need to understand patterns, not just one IP
- Offline ACE snapshots (CSV + SQLite) for restricted environments or local processing
If you want to see what FraudGuard can do in your stack, start with the simplest integration: call the API on traffic that matters (auth, signup, checkout, etc.), then use the result to allow, challenge, or block.
Want a quick walkthrough? Start with the FraudGuard API guide.
Full API reference documentation is here: docs.fraudguard.io.
Prefer a free IP lookup first? Try IP Lookup.
Want to see plans and pricing? fraudguard.io/pricing.
Disclosure
This article is part of the DigitalOcean Ripple Writers program. I received compensation and platform credits for writing this content, but all technical assessments, architecture decisions, and opinions are my own based on hands-on production use.
Put the evidence to work
Turn an IP signal into a defensible decision.
Investigate a source with FraudGuard, then bring explainable allow, challenge, and block decisions into your own request path.